Speech to Text and Image
GitHub Repository: https://github.com/Ashot72/Speech-to-Text-to-Image
Video Link: https://youtu.be/ZI6Q60PrUCE
I just built an app where you can record your voice and see the text extracted from your voice and the image generated.
I generated images from texts using Replicate. Replicate https://replicate.com/blog/machine-learning-needs-better-tools runs machine learning models on the cloud. They have a library of open-source
models that we can run with a few lines of code.
Figure 1
You can sign up and get you api key to use it in the app. Seems you can generate some images free at some point.
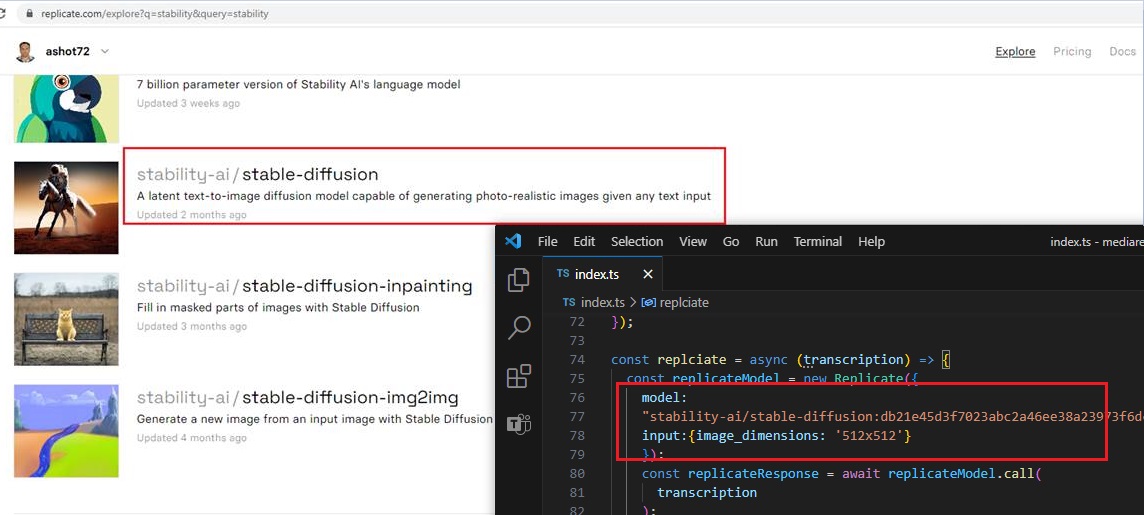
Figure 2
You see we use open-source stability-ai stable-diffusion model to generate an image from a text.

Figure 3
It generates images that we save in our app.
I turn my audio into text using Whisper https://openai.com/research/whisper which is an OpenAI Speech Recognition Model that turns audio into text with up to 99% accuracy.
Whisper is a speech transcription system form the creators of ChatGPT. Anyone can use it, and it is completely free. The system is trained on
680 000 hours of speech data from the network and recognizes 99 languages.
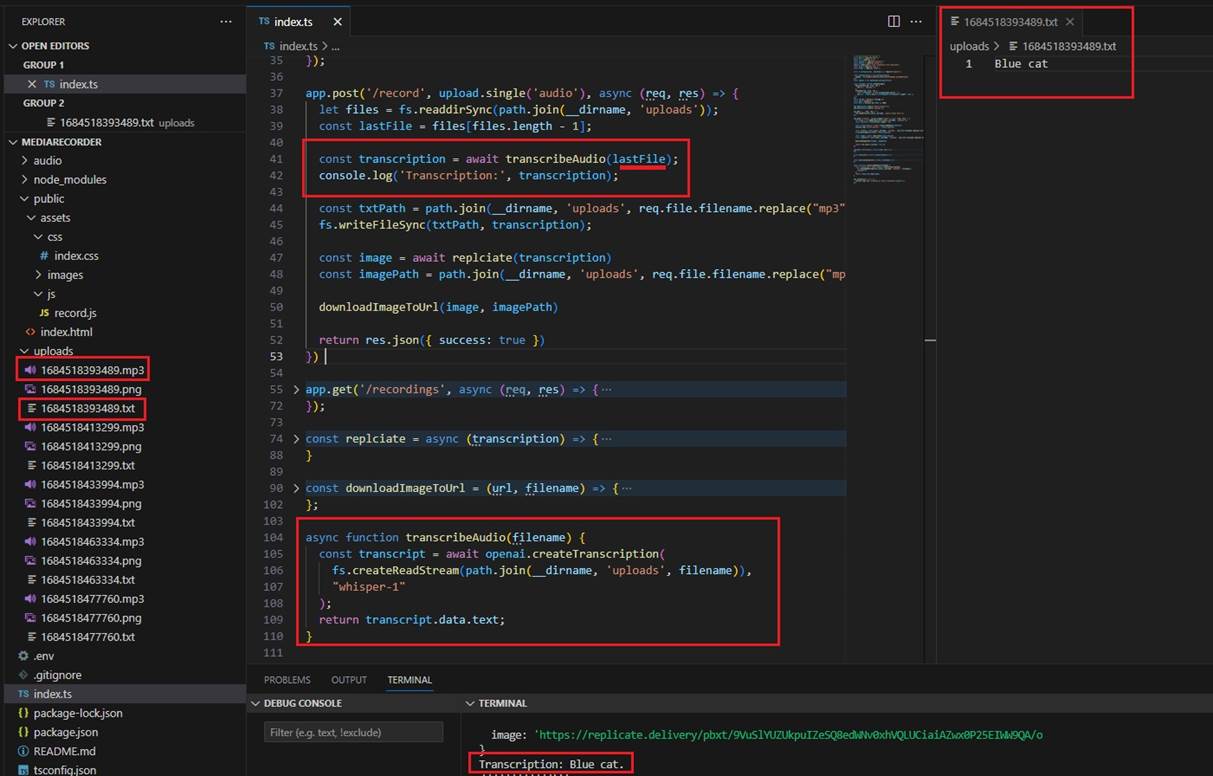
Figure 4
We pass an audio to whisper and get the text form it then saved it into a file.
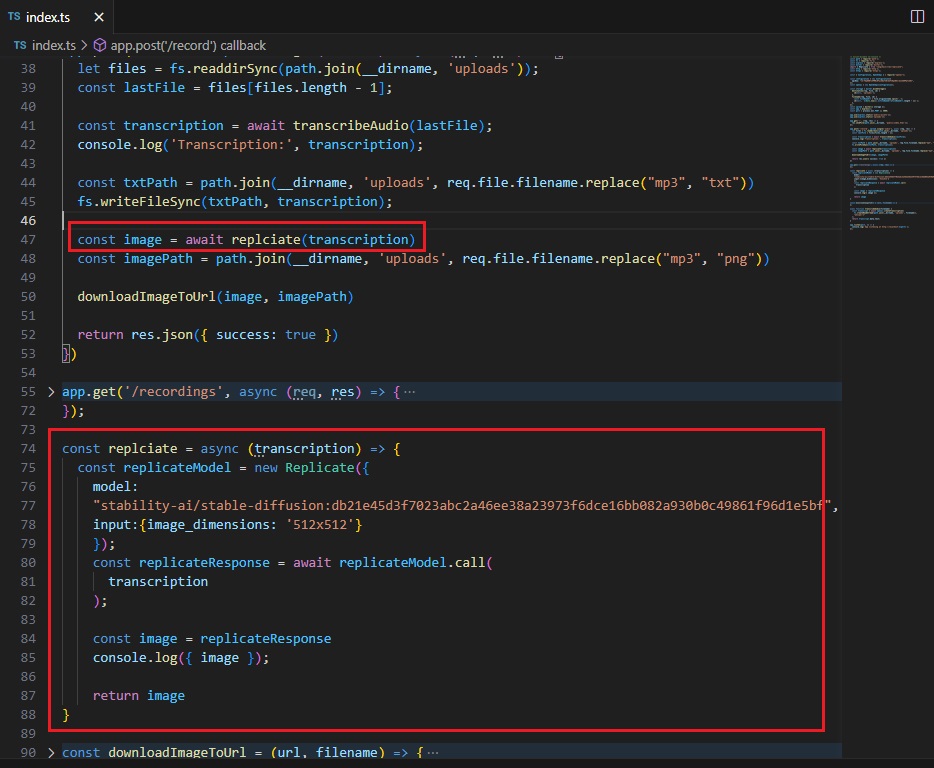
Figure 5
Once we have a text, we generate an image from it.
Figure 6
Note, that we do not explicitly specify API keys in the code. It will be picked up from .env file when specified as OPEN_API_KEY and REPLICATE_API_KEY.