Running the Multimodal AI Chat App with Ollama Using a Locally Loaded Model
Video Link: https://youtu.be/IuoUJ2dJiGw
GitHub Repository: https://github.com/Ashot72/Ollama-local-chat-app
We would like to explore how to run large language models (LLMs) locally on our machines, such as our laptops. If we don't have a supercomputer at home, then
we need to find a way to run them efficiently. You can read more about it on my LM Studio Local Chat App GitHub page, including information about quantization and related topics.
This also applies to Ollama local models
Ollama is a tool and runtime for running large language models (LLMs) locally on your computer. It simplifies the process of downloading, running and interacting with
open-source models like LLaMA, Mistral, Gemma and others without needing to set up complex environments or use cloud-based services.
Figure 1
First, we have to download Ollama.
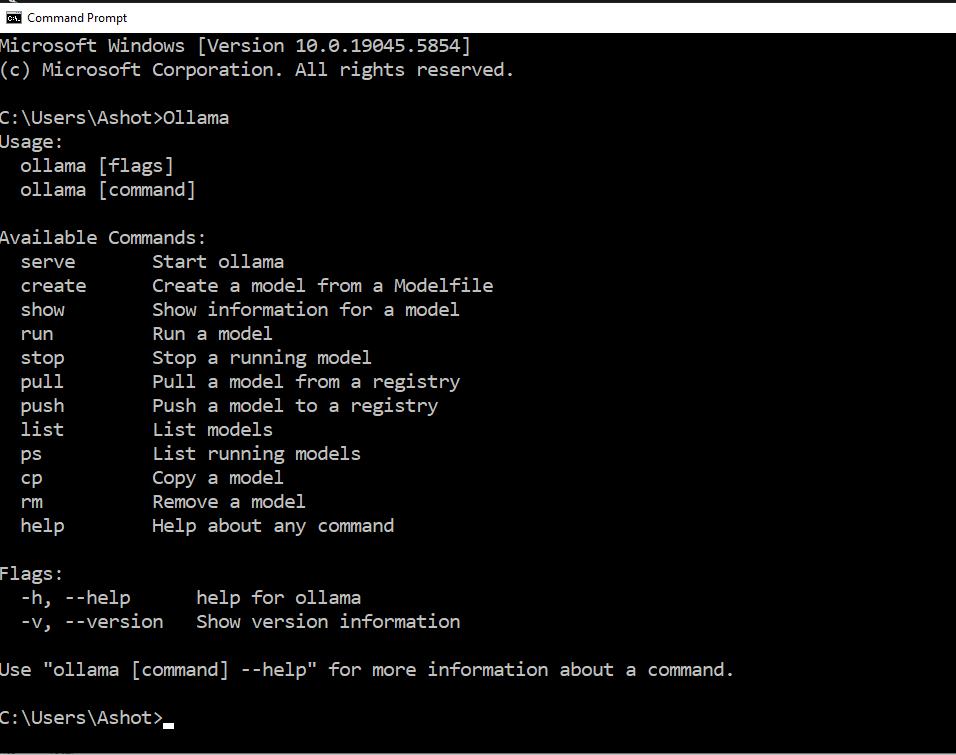
Figure 2
To verify if Ollama is installed, open your system's terminal and run the Ollama command. If it's installed correctly, the command will execute without errors.
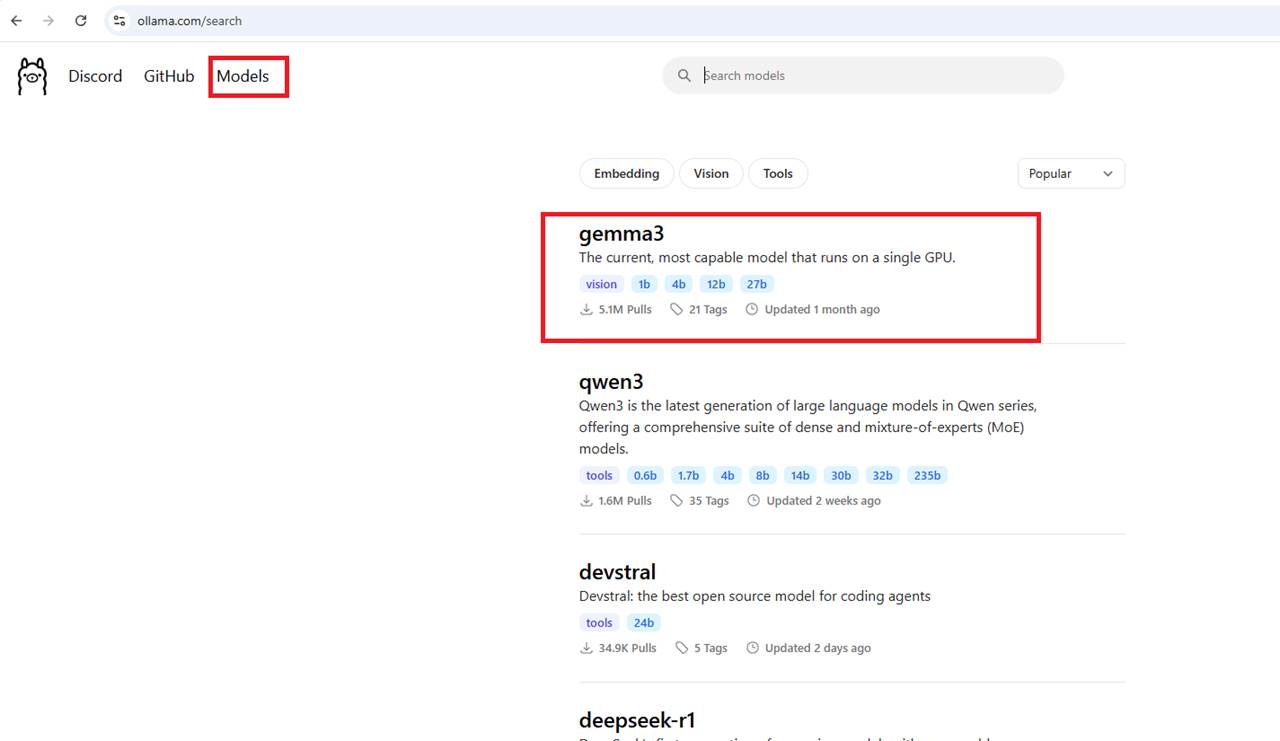
Figure 3
To run a model, we first need to select one from the model's catalog on the Ollama website. All models provided there are quantized for efficient local performance.
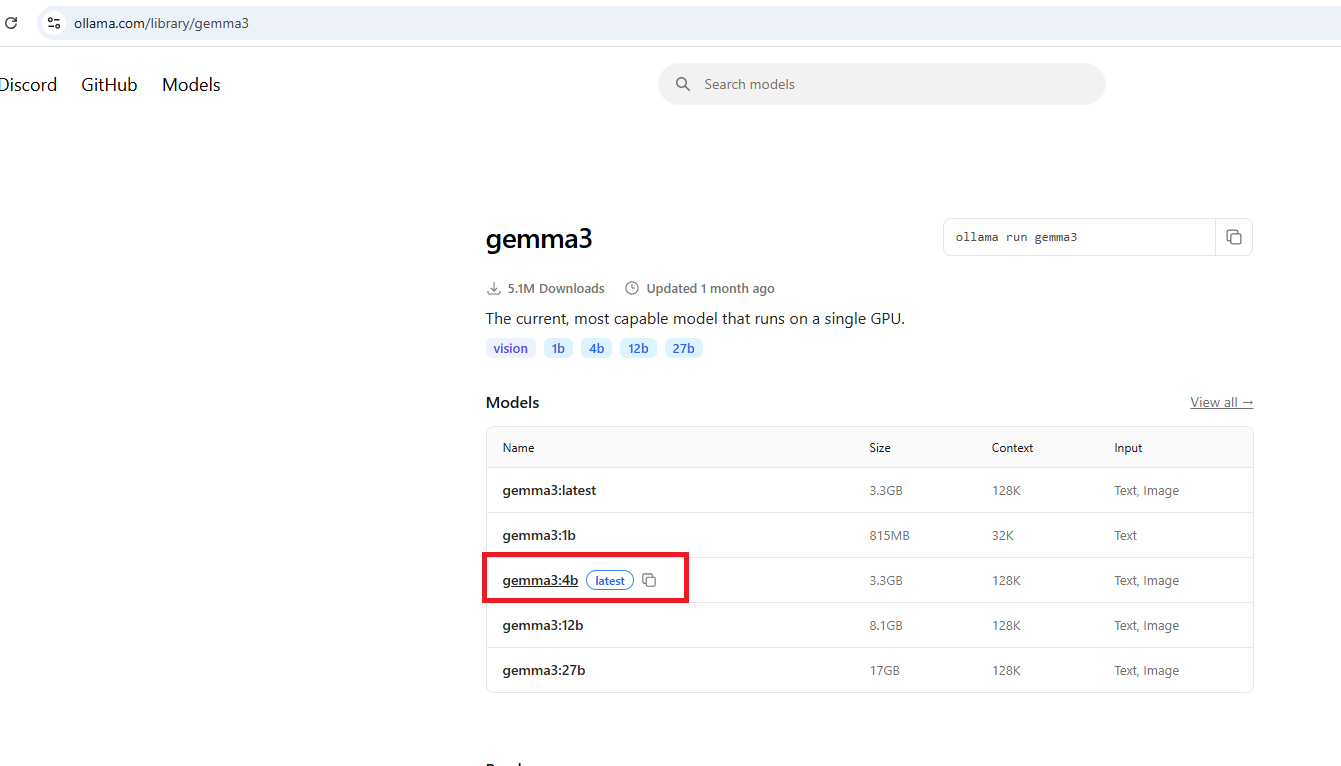
Figure 4
We will use the gemma3:4b model.
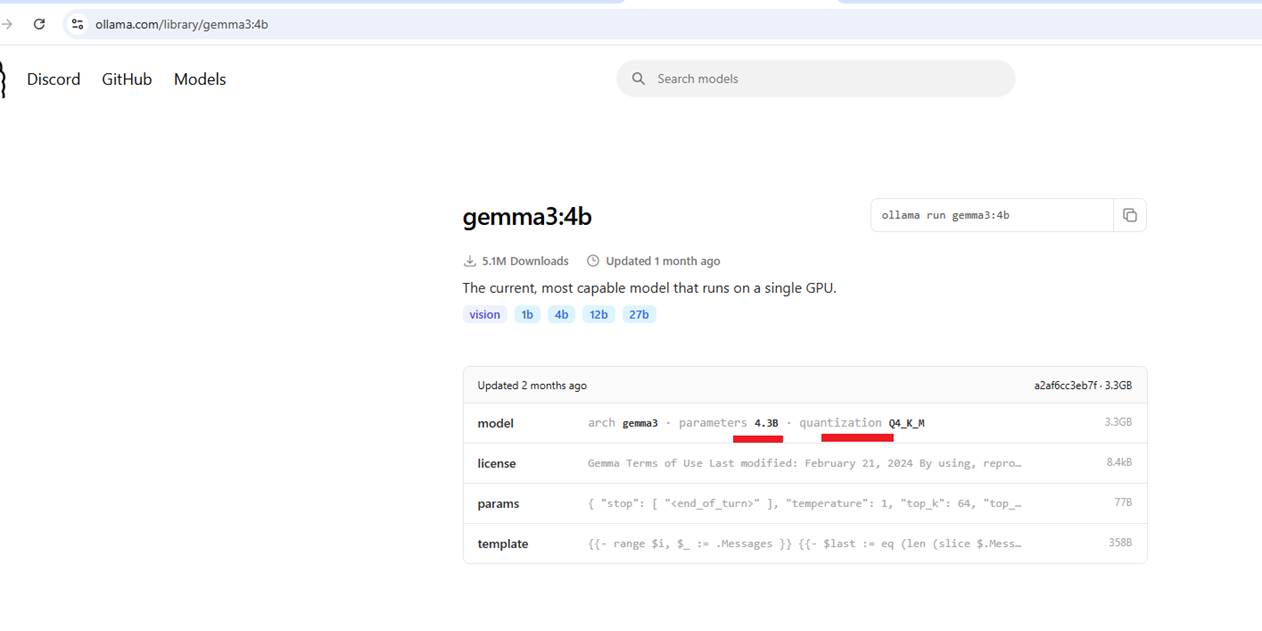
Figure 5
The model has 4.3 billion parameters and is quantized. To download the model, use the command ollama pull gemma3:4b, which will download the model. Alternatively, you can
use ollama run gemma3:4b, which will both download and run the model. If you use the pull command first, then once the model is downloaded, you can run it anytime with
ollama run gemma3:4b. This command will not download the model again; it will just run it since the model is already downloaded.
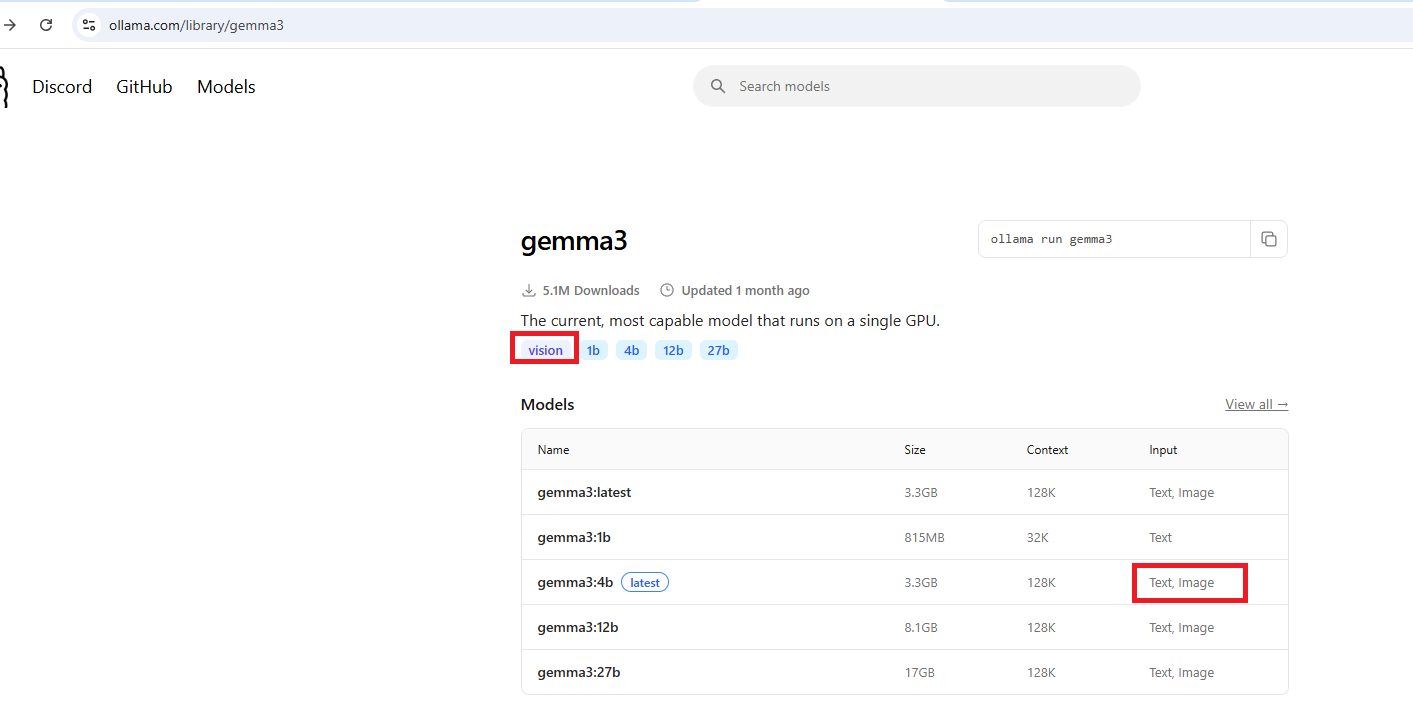
Figure 6
The model we chose has vision support, meaning it can understand images as input.
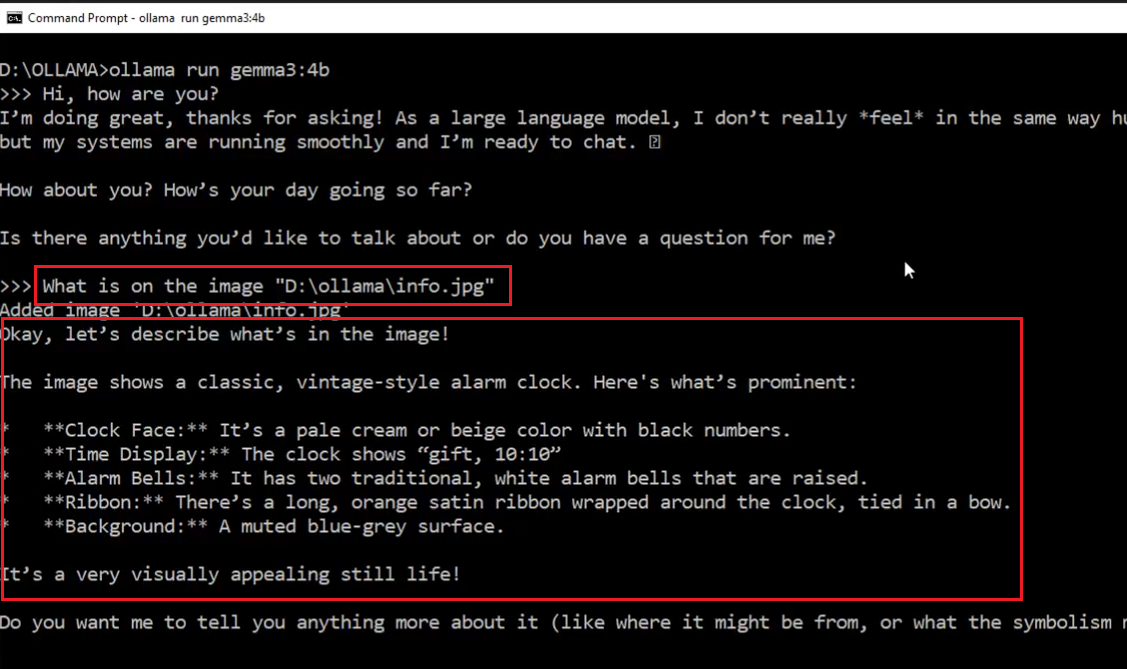
Figure 7
We provided an image as input, and the gemma3:4b model was able to describe it. In the video, you can see that when we run the model, it allows us to specify several
commands such as show info, show parameters, set parameters, run in verbose mode to get more details, set system prompt, show system prompt, and more.
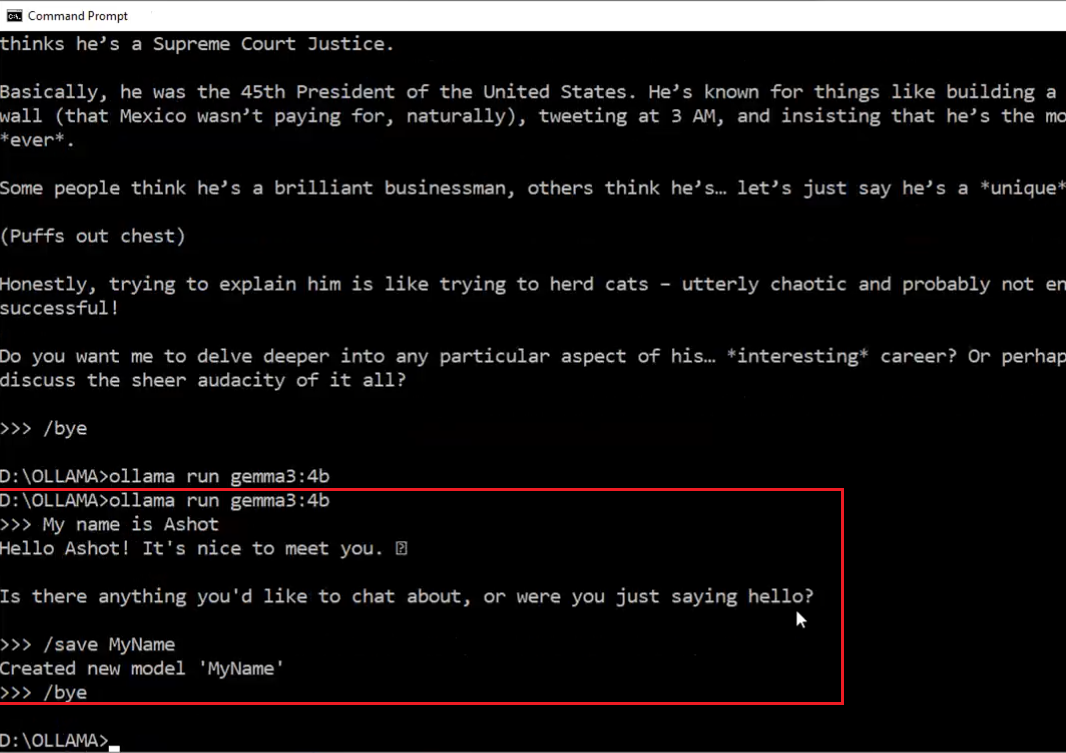
Figure 8
With Ollama, we can save chat sessions. Although Ollama calls it 'saving a session,' this isn't exactly the correct term. For example, if I say, 'My name is Ashot,' and save
the session as 'MyName,' Ollama says it's creating a new model called 'MyName.' After that, we can quit and run the model again using that saved session.
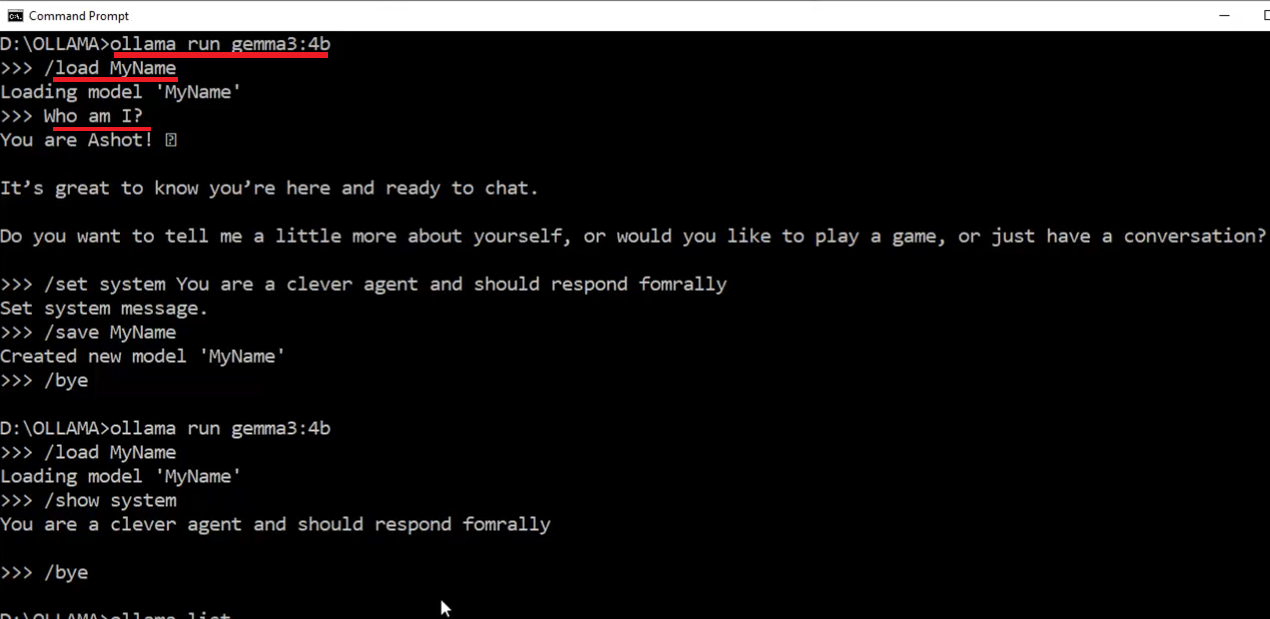
Figure 9
I ran the model again and loaded the saved session, and you can see it remembered my name even though I didn't share it in the current chat session here.
I had shared it earlier in the saved session called 'MyName.' Technically, Ollama doesn't just save and load chat sessions like a simple transcript. Instead, it creates a copy of the
model that includes the previous chat history embedded in its initialization data. So, whenever you load or run that saved model, it starts with the entire chat history it had when
the session was saved.
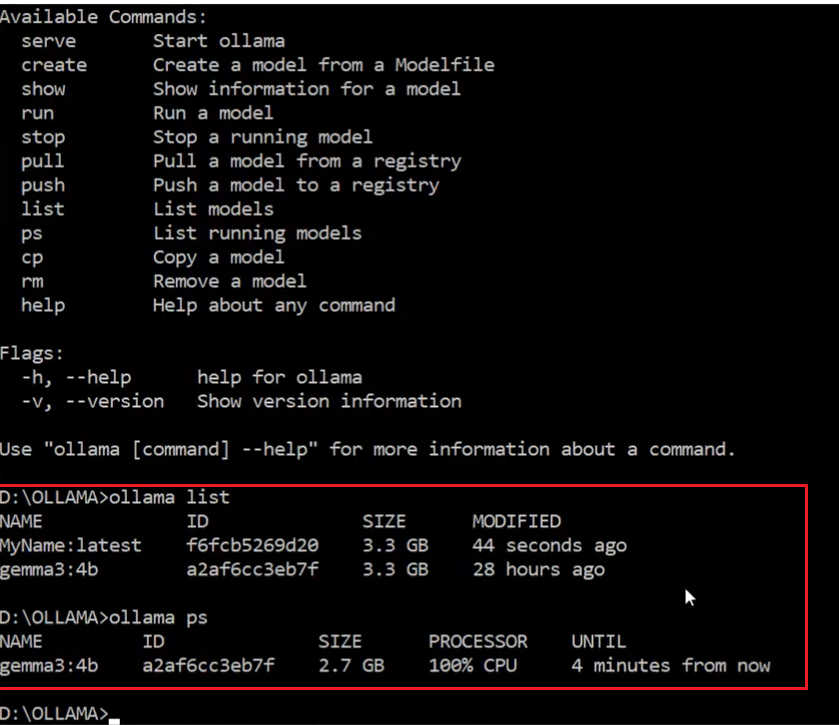
Figure 10
When running ollama list, we see the list of available models, and you can see that the 'MyName' model is listed. Using the ollama ps command shows the models currently running;
in this case, it shows that gemma3:4b is running. Ollama keeps models running in memory for five minutes, and if there is no activity for five minutes, it automatically removes them
from memory to free up space.
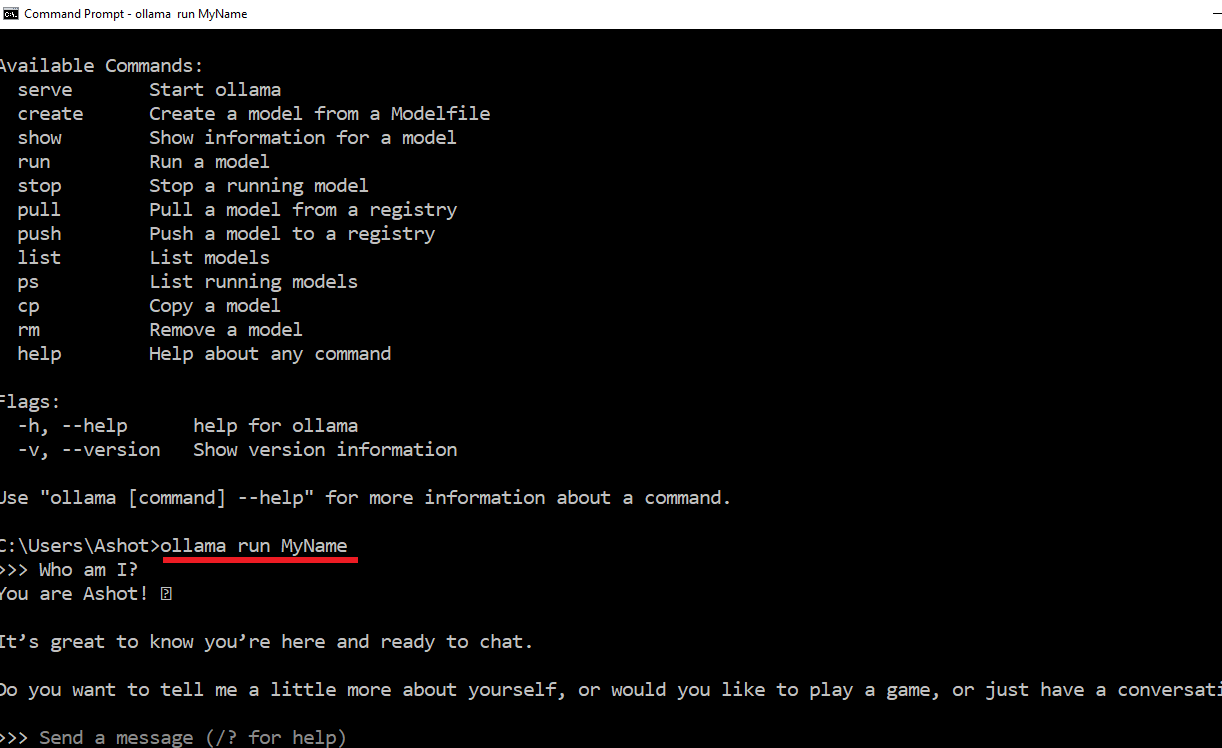
Figure 11
If we run the ollama run MyName command directly, instead of the previous method where we ran ollama run gemma3:4b and then used /load MyName (as shown in Figure 9)
it will start the model with all the settings and chat history that were saved in the 'MyName' session.
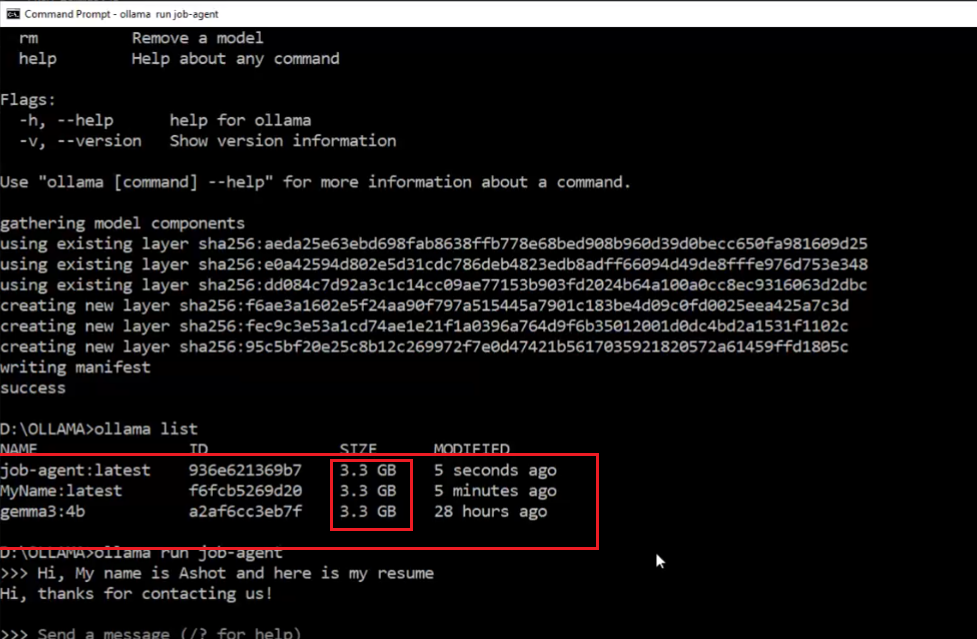
Figure 12
As we work with Ollama, we may end up with more and more models, resulting in a long list. These models do take up space on your system. Although each model may show a size of 3.3 gigabytes,
Ollama is smart about storage. When you create derivatives such as the 'MyName' model it doesn't make full copies of the base model. Instead, it references the original model and only
stores the changes. This means you can create customized versions of models without quickly filling up your disk.
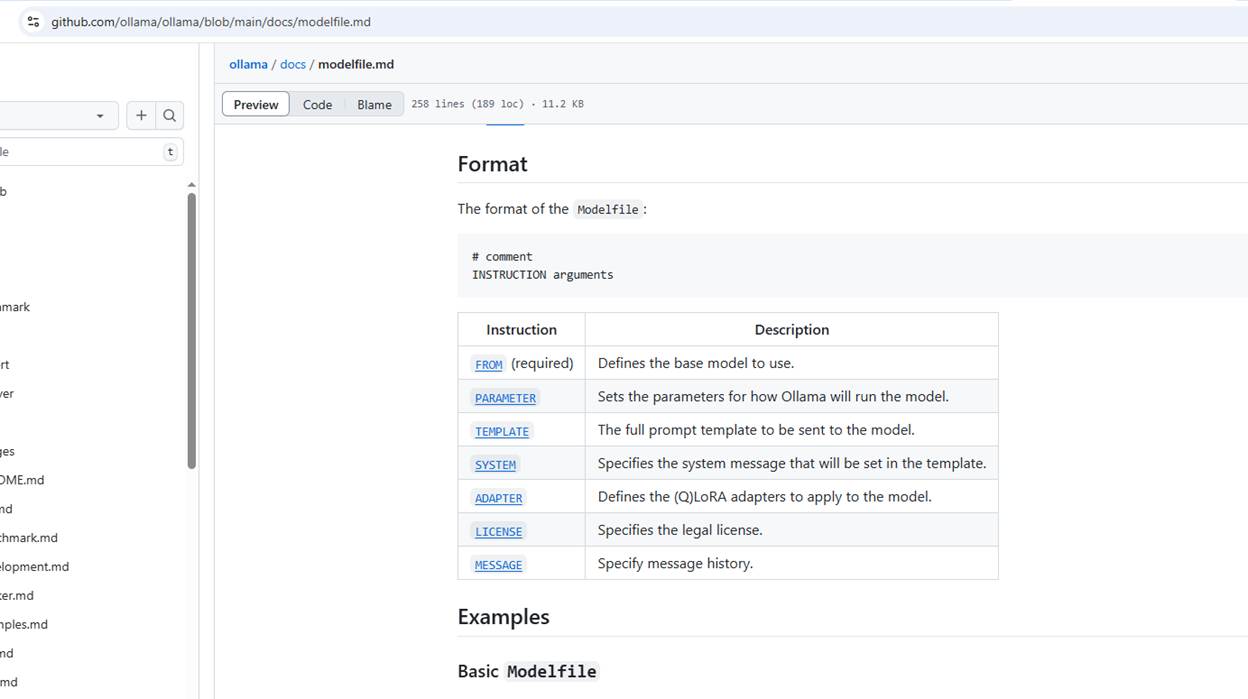
Figure 13
We can also create a model from a Modelfile using the following settings
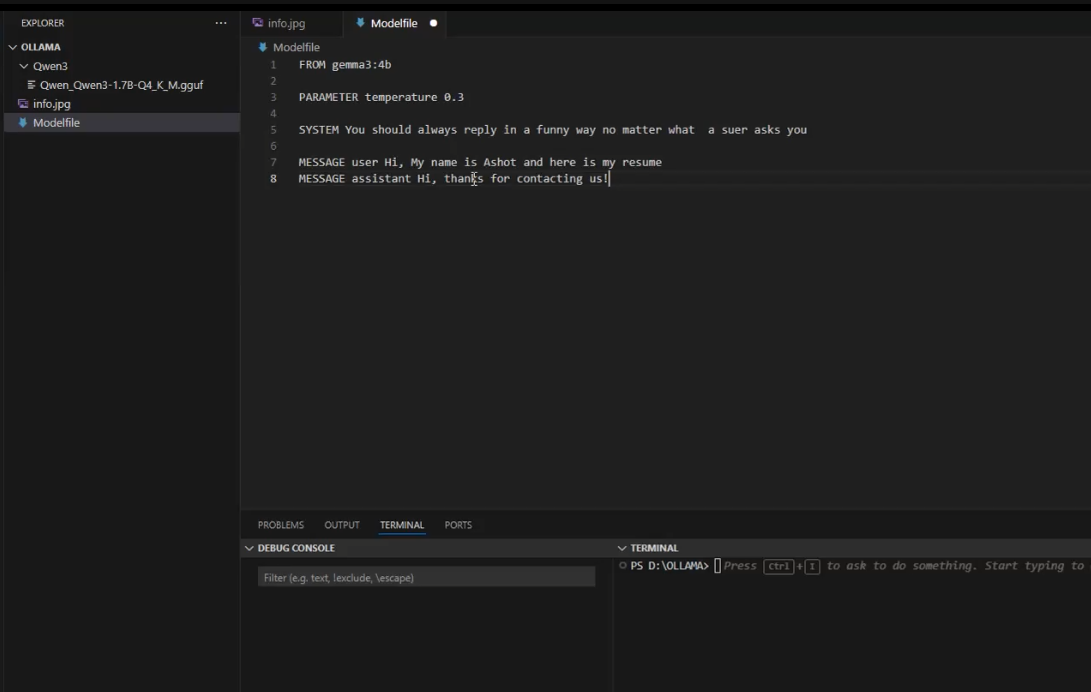
Figure 14
Here, we created a job-agent model by running the command ollama create job-agent -f ./Modelfile.
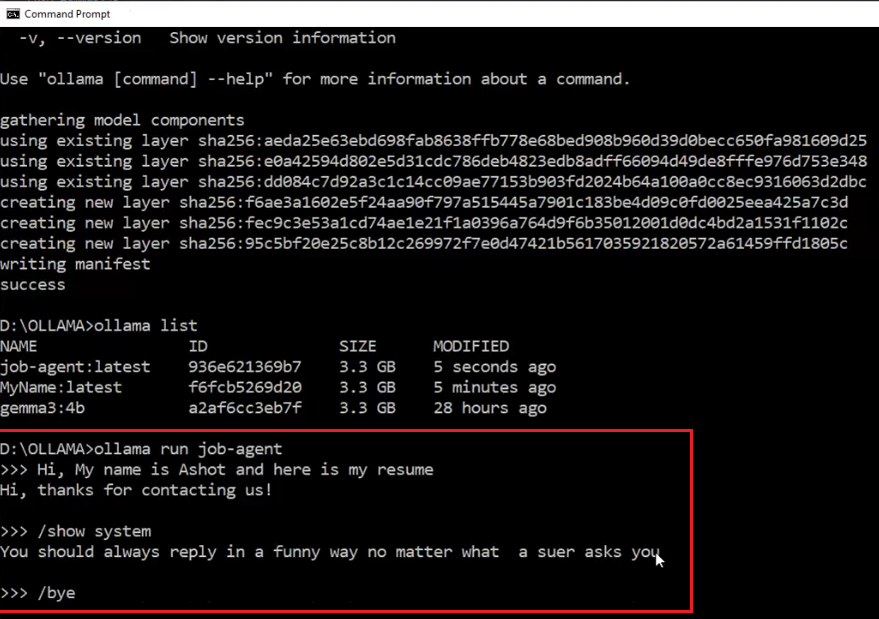
Figure 15
We ran the model and were able to see the chat history between the user and the assistant, as well as the system prompt. The great thing about a Modelfile is that you can share it with others.
You can upload it to GitHub or share it through your website, allowing other people who use Ollama to easily copy and use your customized model version.
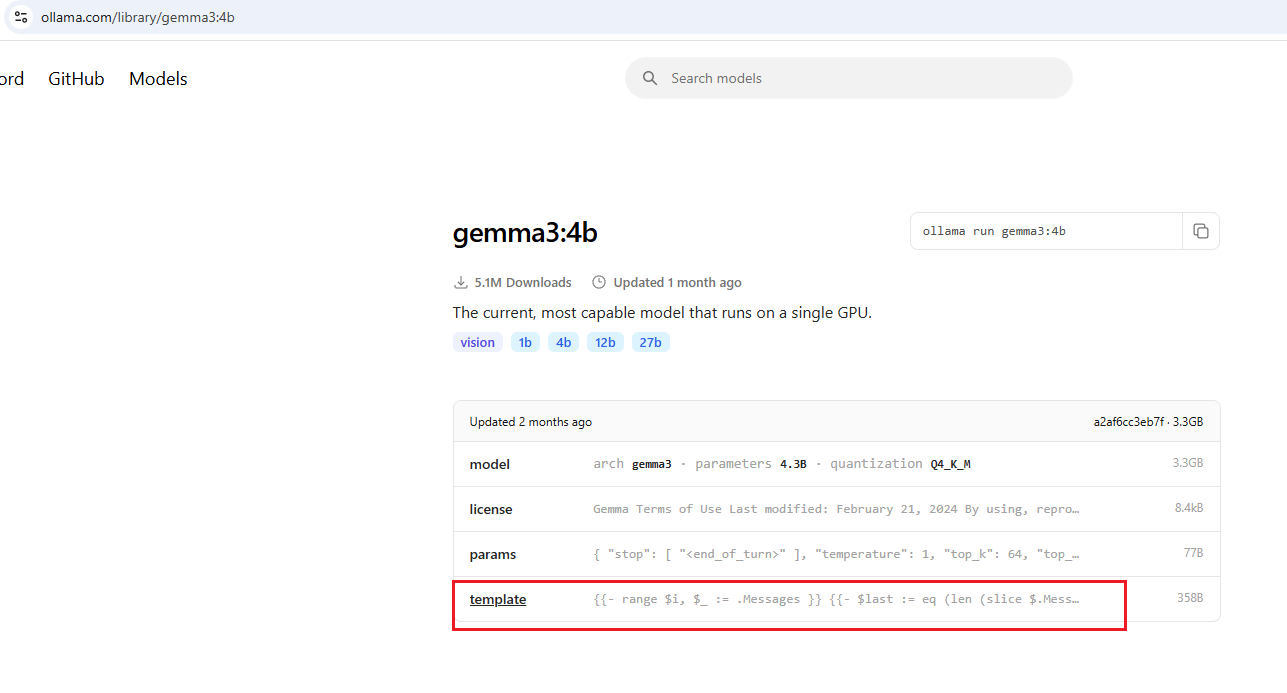
Figure 16
When we go to our model, you'll see something called a template.
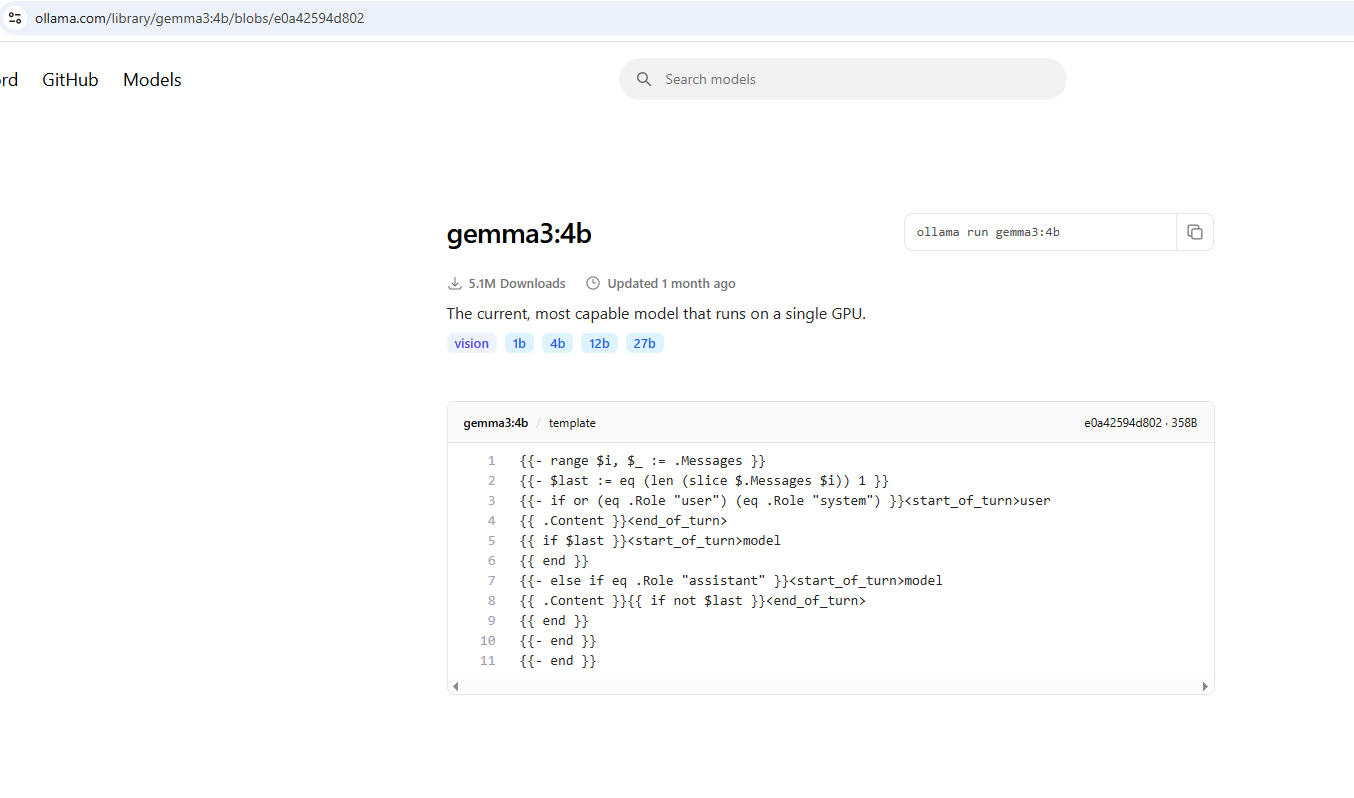
Figure 17
You can see that the template includes some instructions.
This block loops through the messages in a chat and formats them for the model using special tags like <start_of_turn> and <end_of_turn> to help the model distinguish between user
and assistant messages.
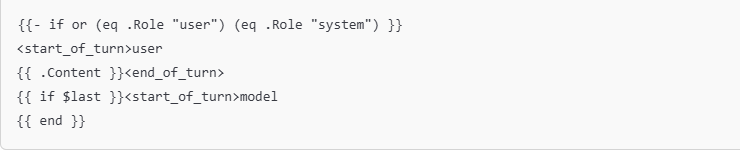
Figure 18
If the message is from the user or system, it wraps the content as a user turn.
If this is the last message, it starts a new turn for the model.
All these LLMs are token generators. They generate tokens based on the input tokens they receive. They don’t inherently understand concepts like system messages, user messages,
or assistant messages generated by an AI. For a model to truly understand elements of chat history such as a system message it must be trained to recognize that certain identifiers in the input
represent specific roles or functions. This understanding needs to be introduced during the training process.
Figure 19
Another way to generate a model is from a GGUF file, for example, one downloaded from Hugging Face. It also includes a 'Chat template' button.
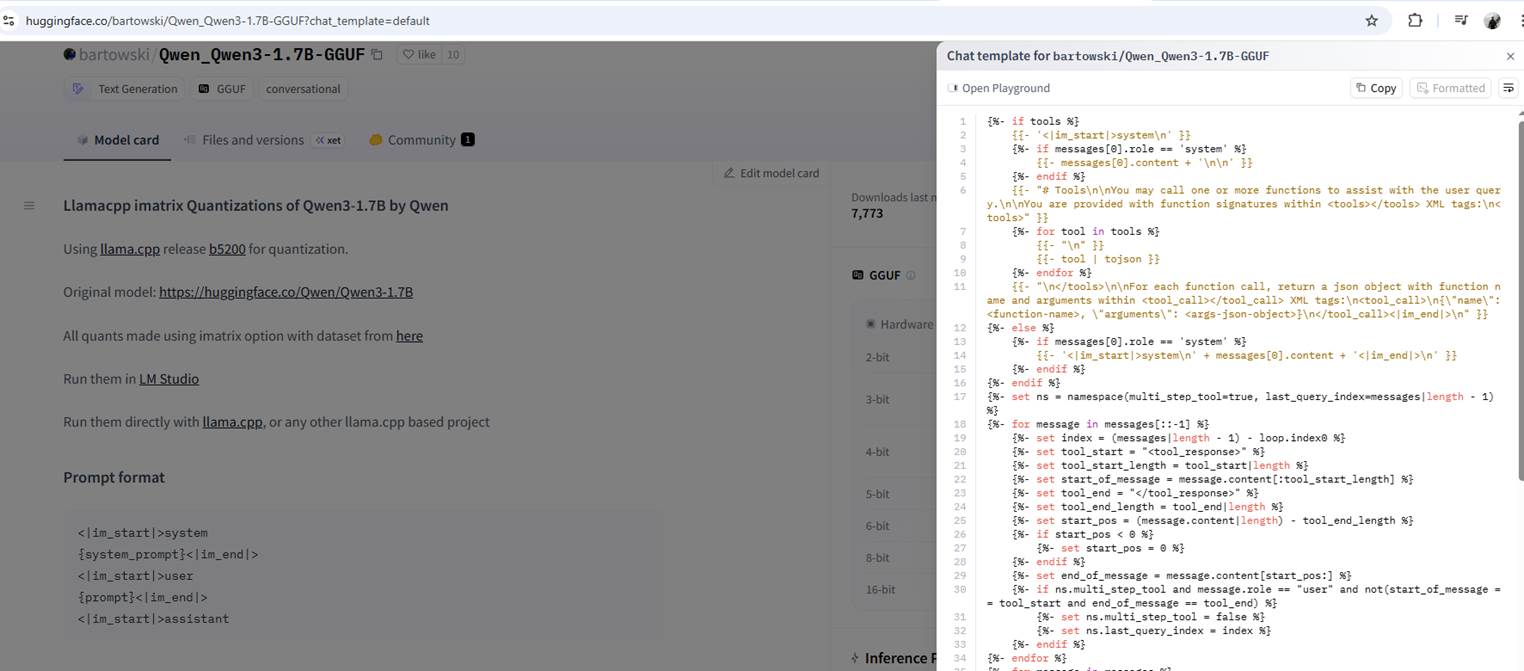
Figure 20
Its template looks even worse than the gemma3:4b template.
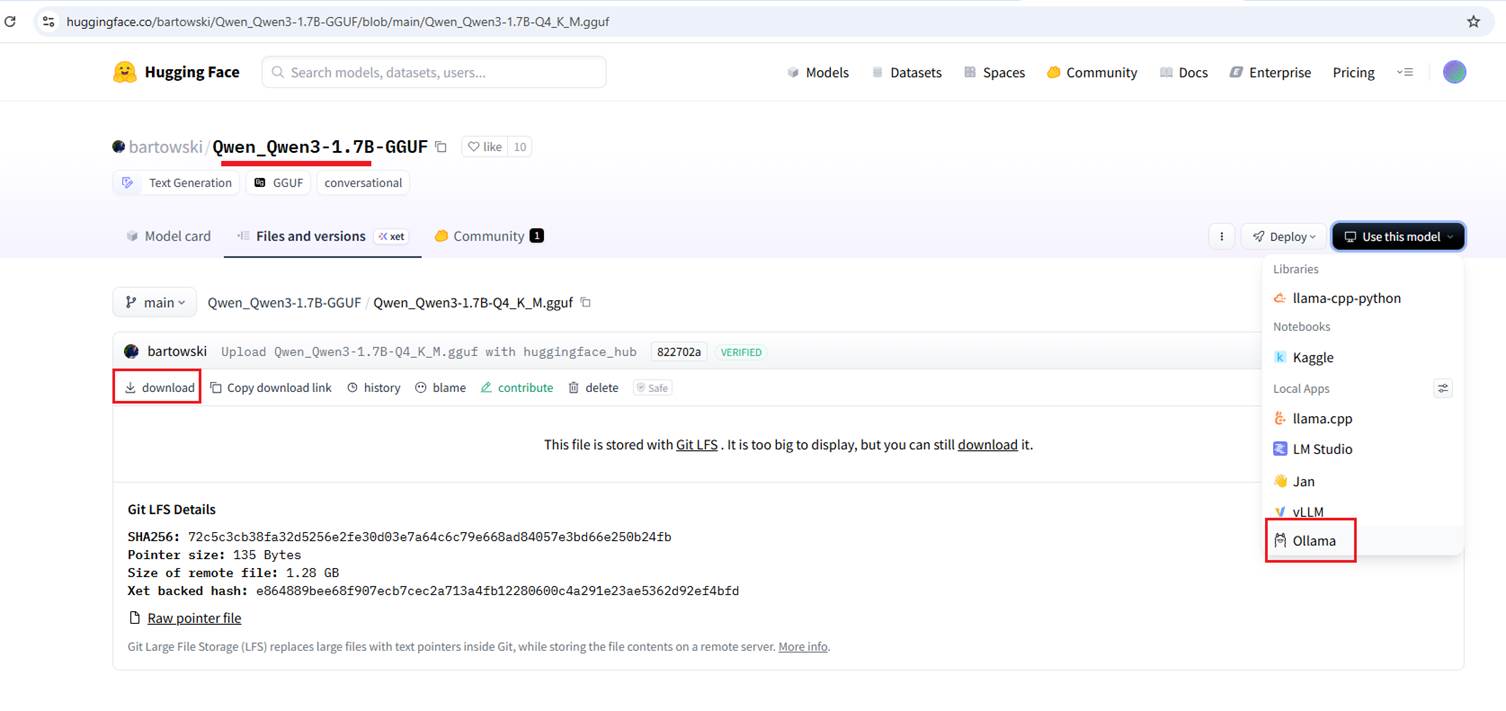
Figure 21
Let’s download the GGUF file from Hugging Face and create a model based on it.
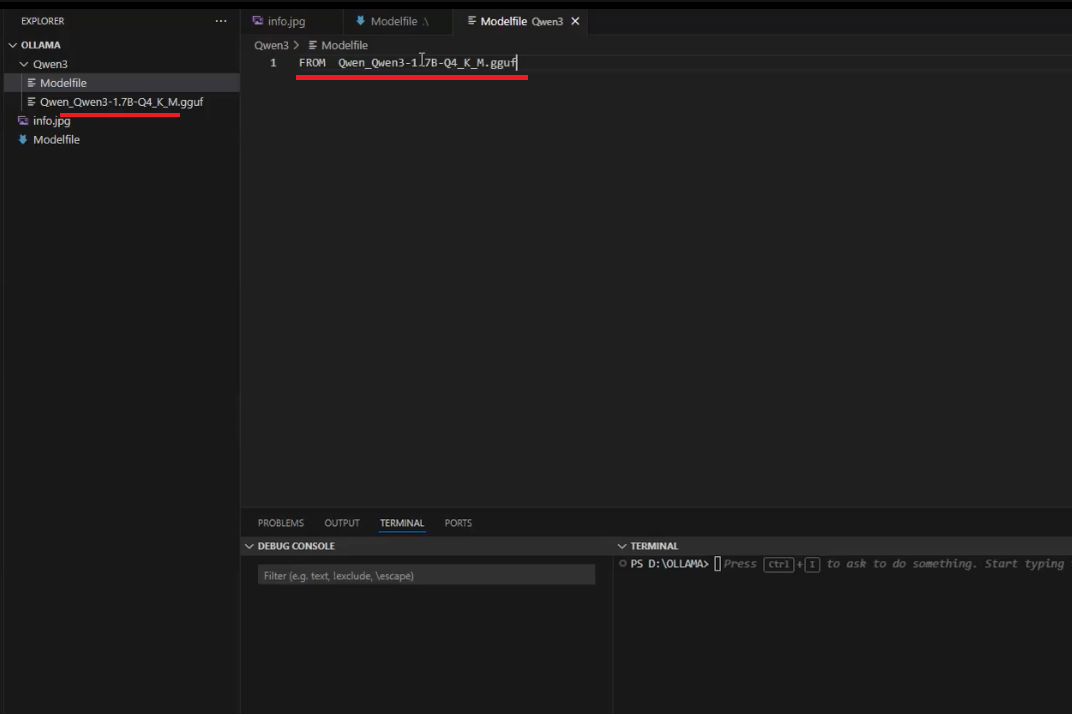
Figure 22
I downloaded the GGUF file and added only the FROM directive, nothing else. Then I tried to create the model using the command
ollama create test-qwen -f ./Makefile.
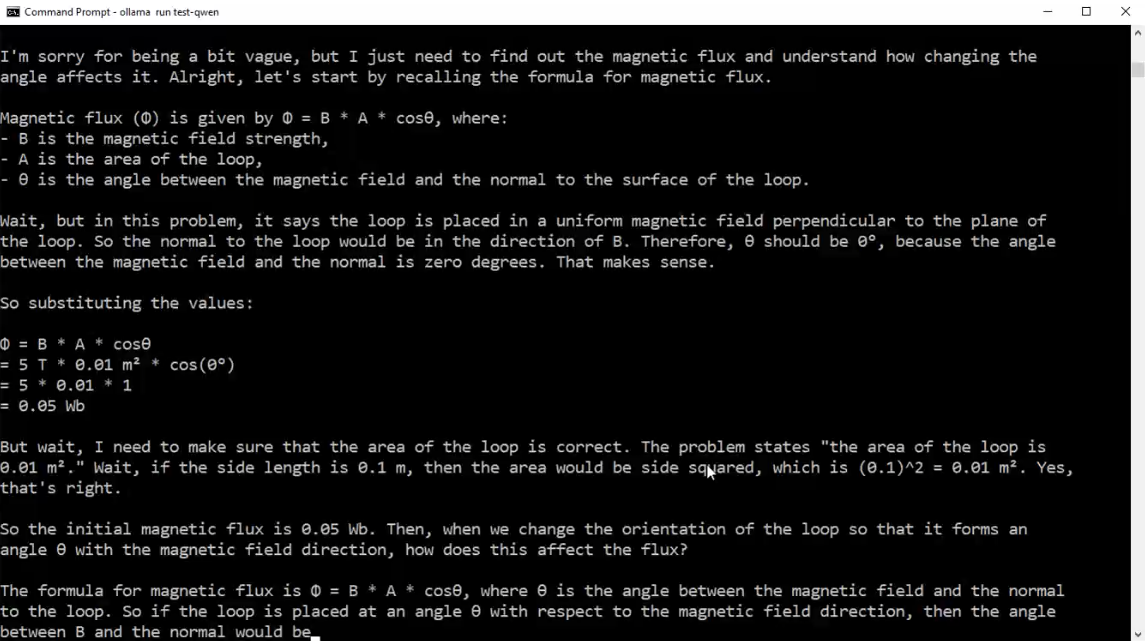
Figure 23
After running it, you see endless information that doesn't make sense to us. The reason is that the model doesn't understand the instructions because there is a
template file it needs to follow. The instructions from Hugging Face (Figure 20) seem different from the instructions for gemma3:4b (Figure 17). The reason is that the
gemma3:4b instructions are written in GO template language, while the Hugging Face instructions are not.
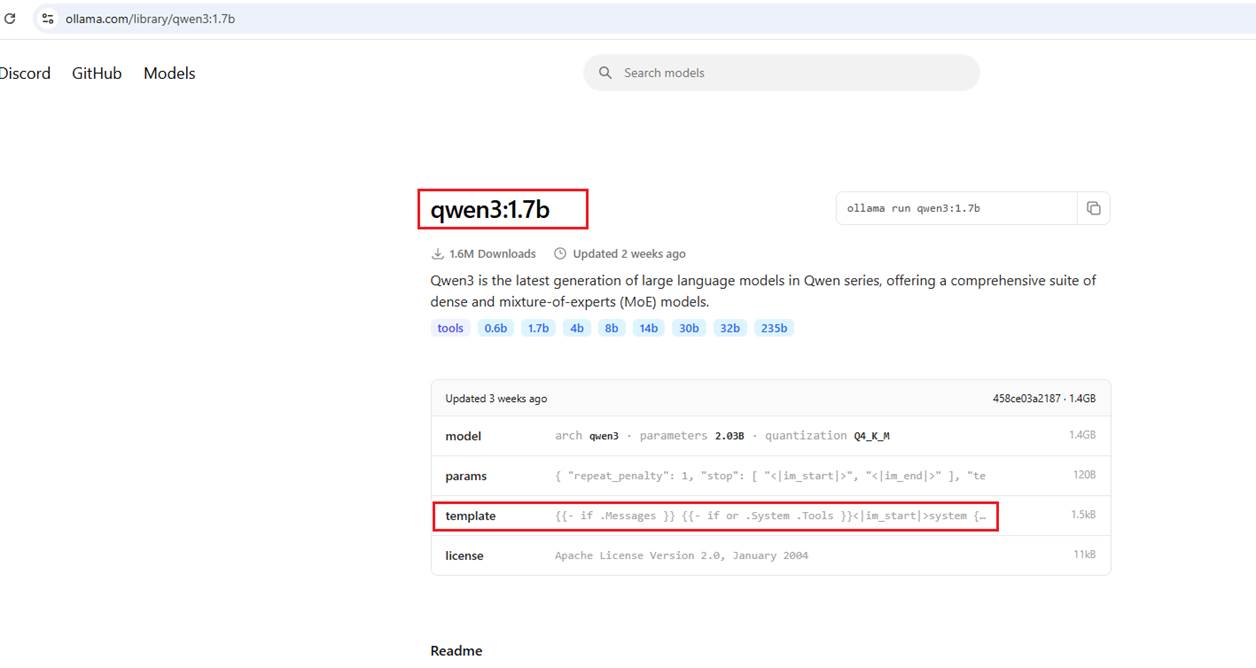
Figure 24
You can see that the Qwen model is also available as an Ollama model, and we can get the instructions from there. Generally, there's no need to get the model from Hugging Face if it's
already available in Ollama. However, if you want to run a model from Hugging Face that isn't available on Ollama, you can obtain the instructions from Hugging Face and potentially use an AI
tool to convert them into Go template syntax for Ollama.
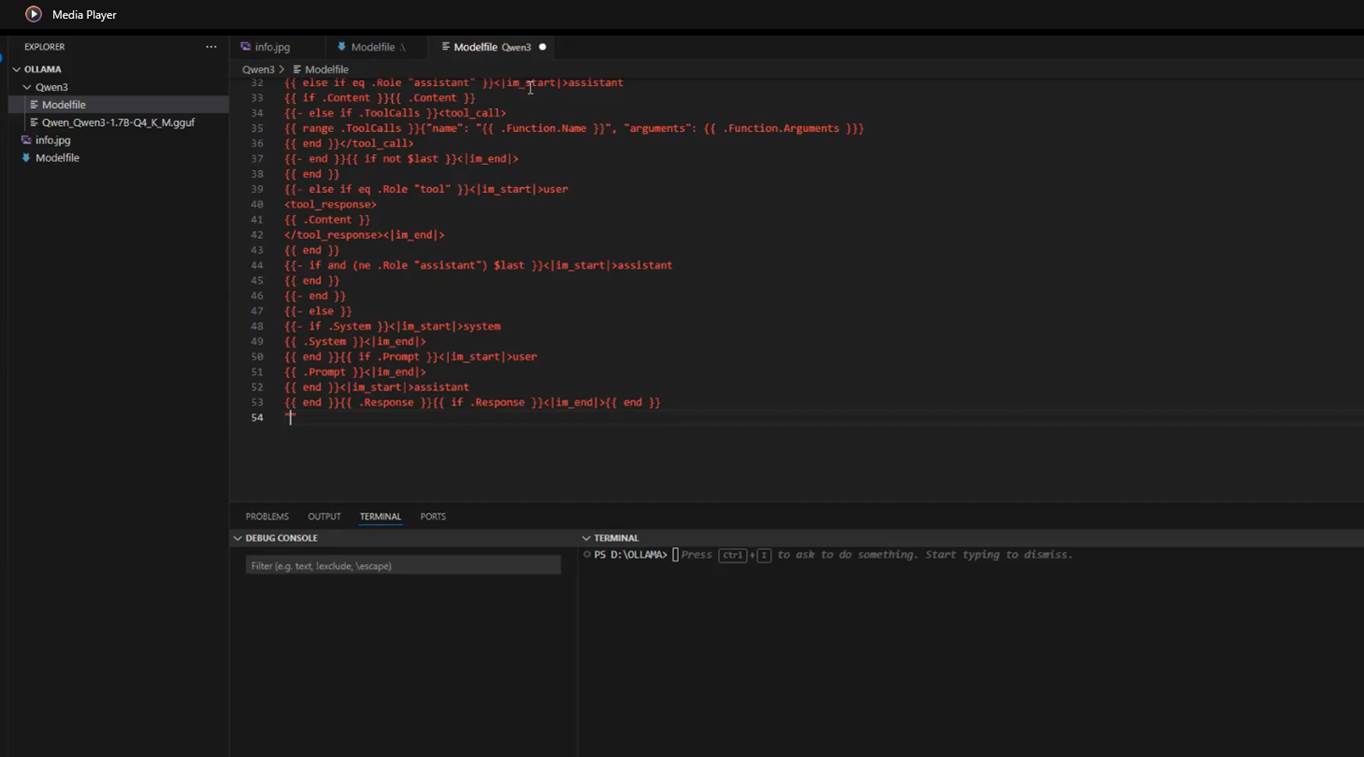
Figure 25
We copy the template from the Ollama page and paste it into the Modelfile inside the TEMPLATE directive.
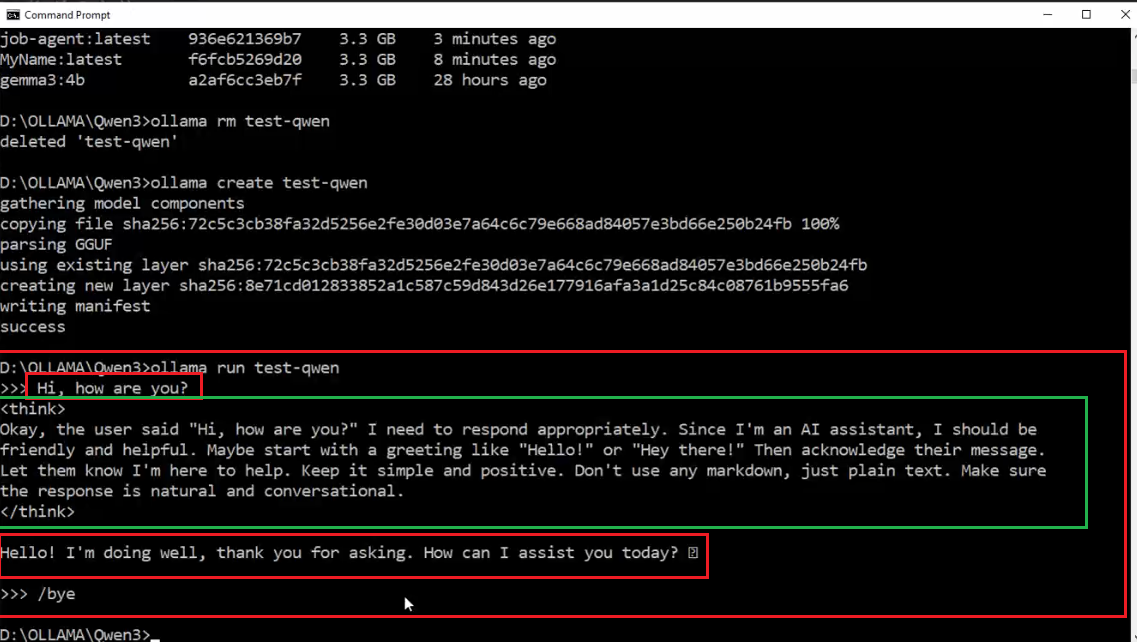
Figure 26
This time, everything works fine. By the way, the Qwen model, developed by Alibaba, is a reasoning model.
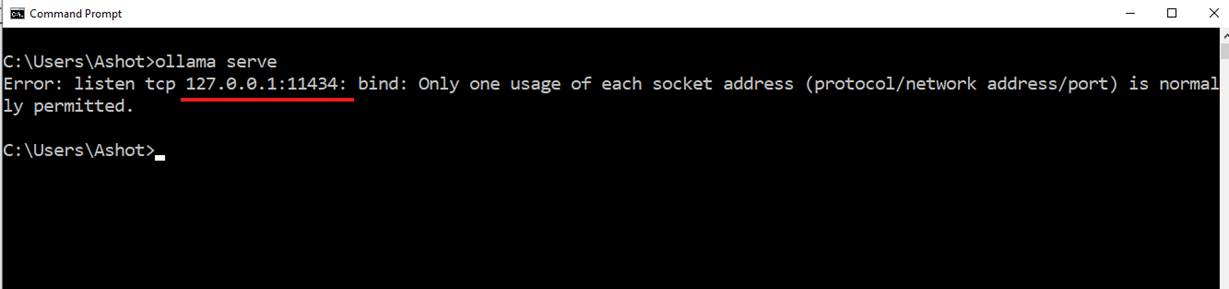
Figure 27
We can use Ollama programmatically, similar to how you would use ML Studio. It runs a server in the background, which you can send requests to from your code. This server starts automatically
when you launch Ollama. If it's stopped for any reason, you can start it manually using the command ollama serve.
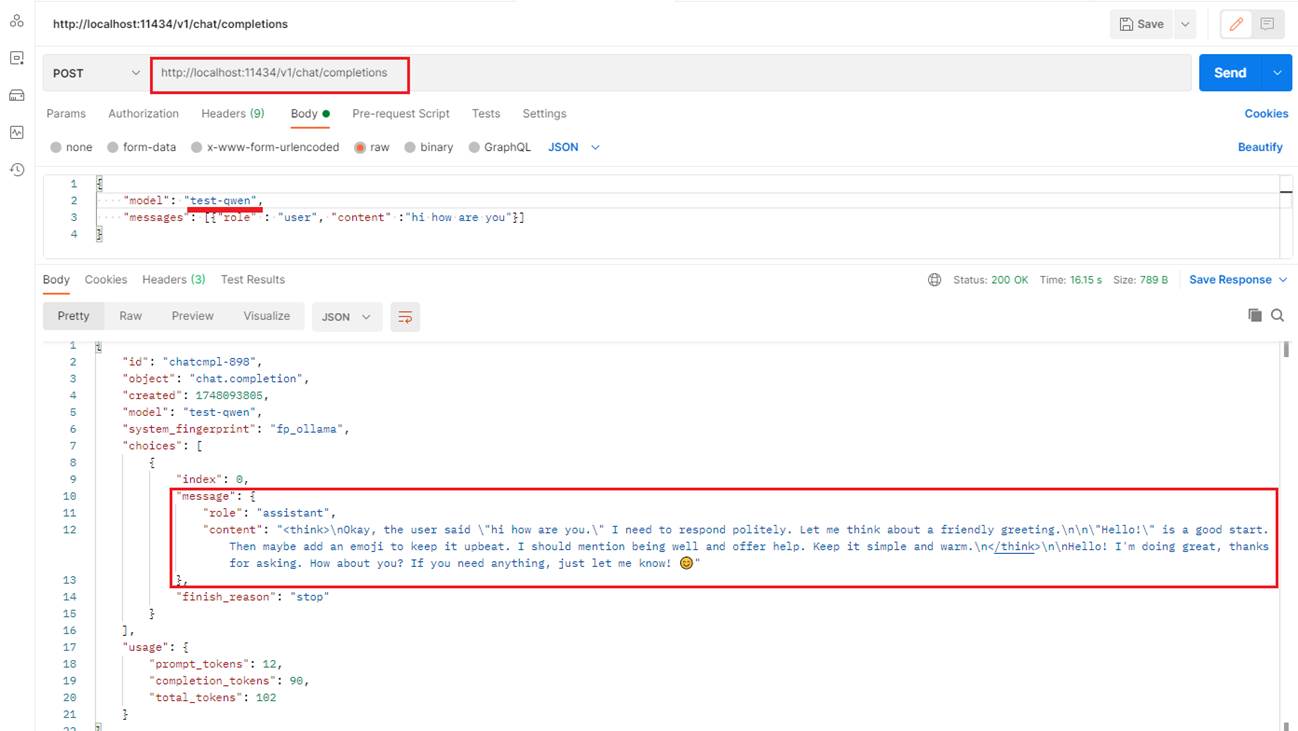
Figure 28
Like ML Studio, one of the great things about these locally running tools is that, besides their own API, they support the OpenAI SDK, which has become the de facto standard for
interacting with LLM APIs.I used my custom test-qwen model, which is based on the original Qwen model.
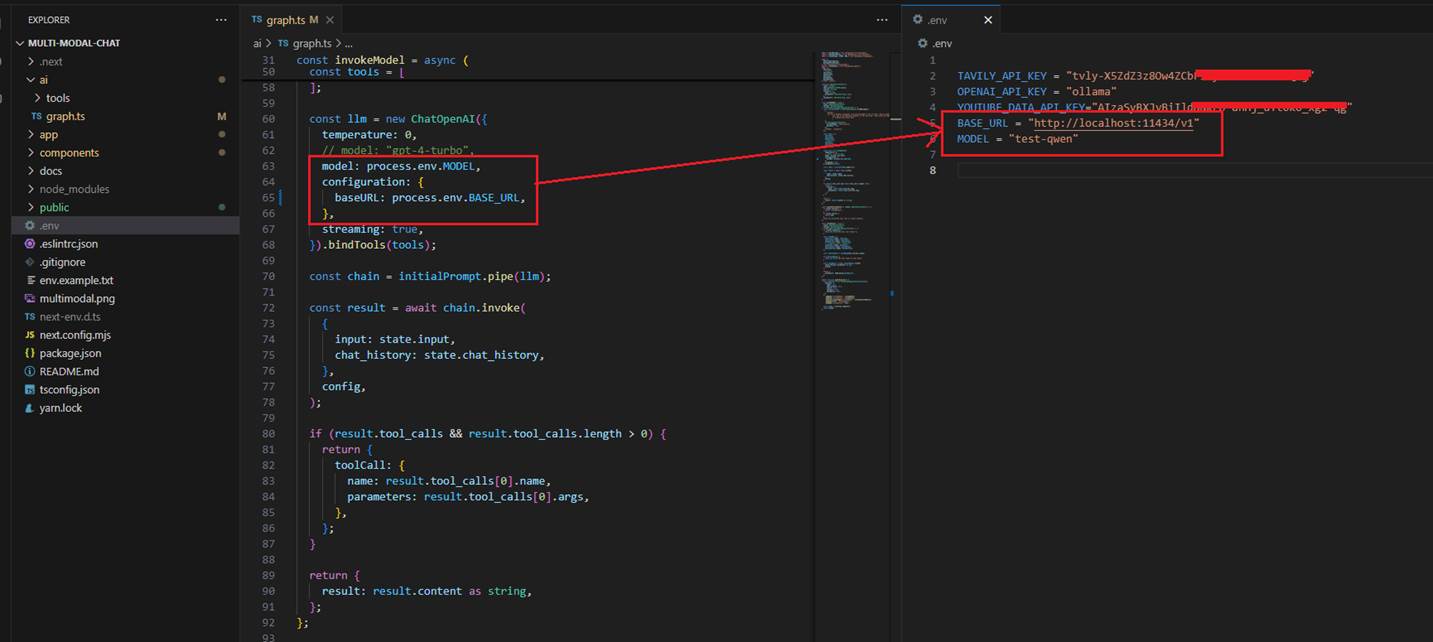
Figure 29
I previously created a multimodal chat application that connected to OpenAI to use their LLM. To make the same app work with a local LLM, I changed only two things, nothing else.
I updated the baseURL to point to the local server (just the base URL, not the full completion path like in Postman) and specified the model's name. There's no need for an OpenAI API
key since everything runs locally. It works because the Ollama server supports the OpenAI SDK.
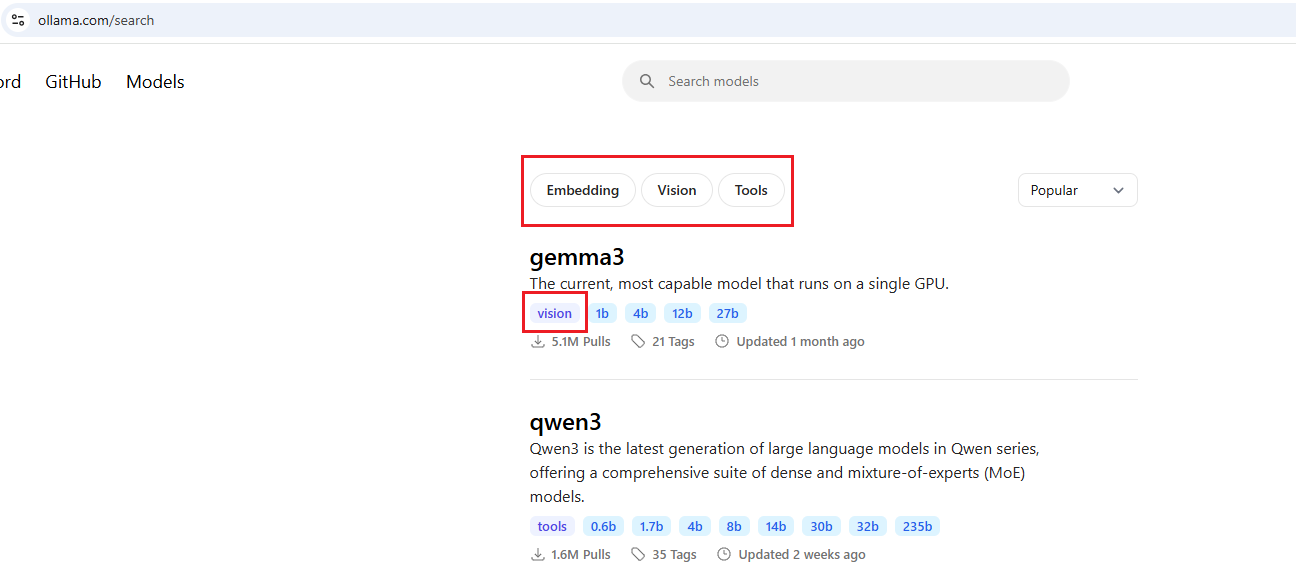
Figure 30
On the Ollama models page, you can see what functionality each model supports. For example, Gemma3 supports vision but not tools. Our chat app relies on tool support
for instance, when you ask about something like a YouTube video, it uses a tool to fetch that information. This means if you specify the model gemma3:4b, the chat app won't work
properly because the model doesn't support tooling
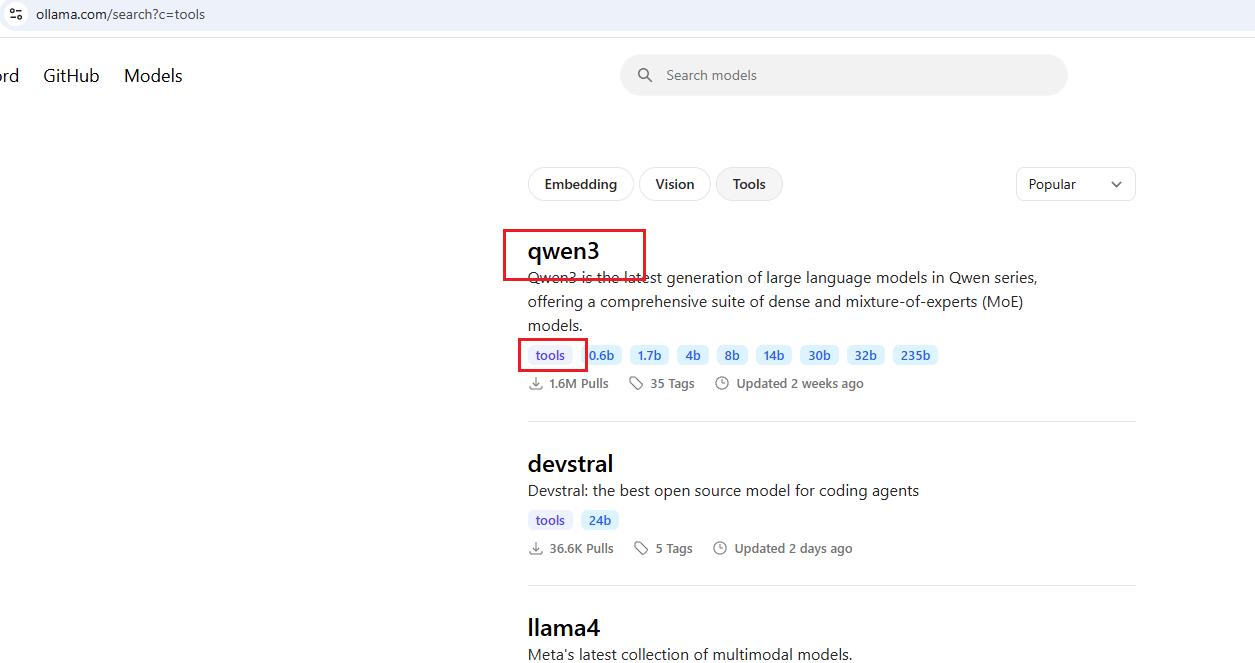
Figure 31
On the other hand, Qwen3 supports vision but not tools. This means that the chat app will not work with this model.
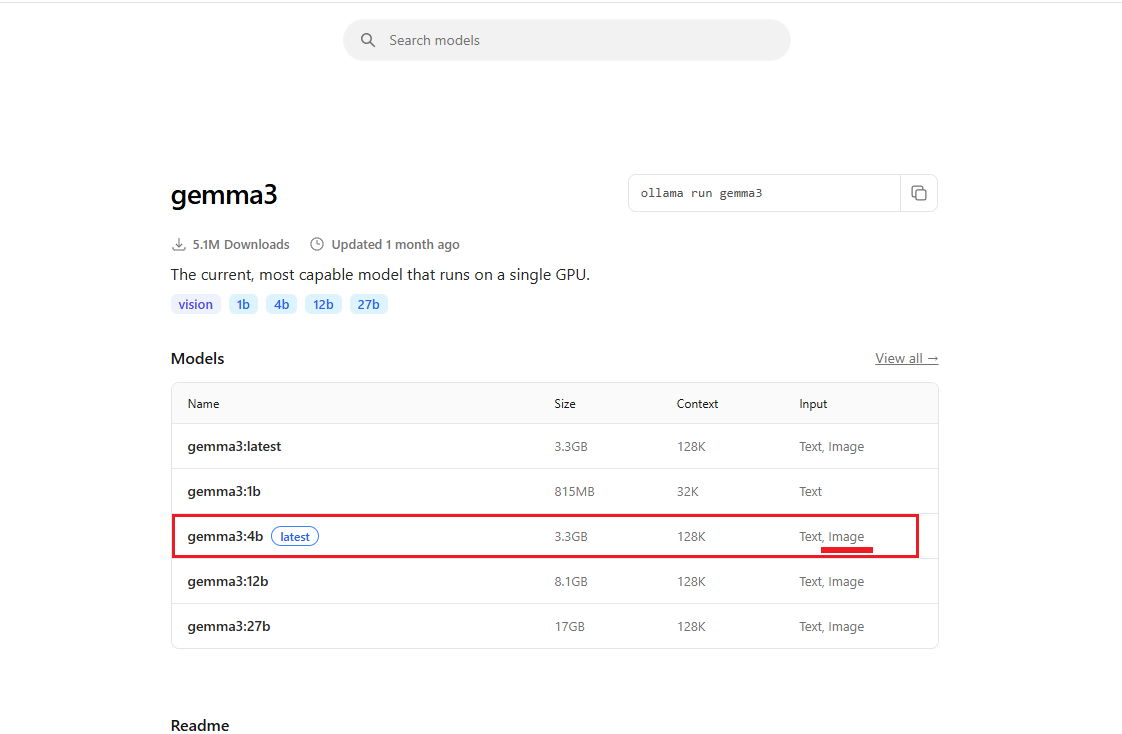
Figure 32
When we say Gemma3:4b supports vision, we specifically mean it can understand images. In the chat app, you can upload a picture and ask the model to describe it.
So, Gemma3:4b supports vision but no tools, whereas Qwen3 supports tools but no vision.
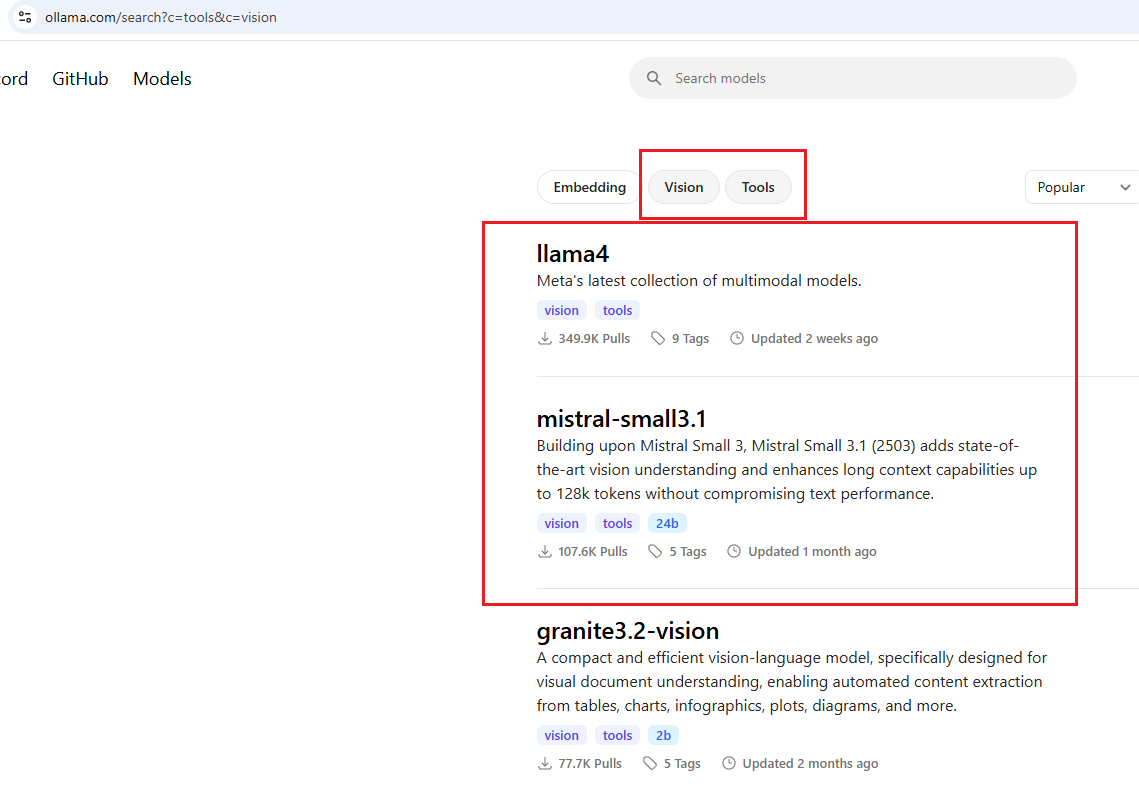
Figure 33
We should choose a model that supports both tools and vision. There are basically three models in this category, but the Granite-3.2 version, although small in size, unfortunately
does not support images. The first two models fit the chat app's requirements but are relatively large: Llama4 is 67GB, and Mistral-small3.1 is 15GB, which are not feasible to run on my machine.
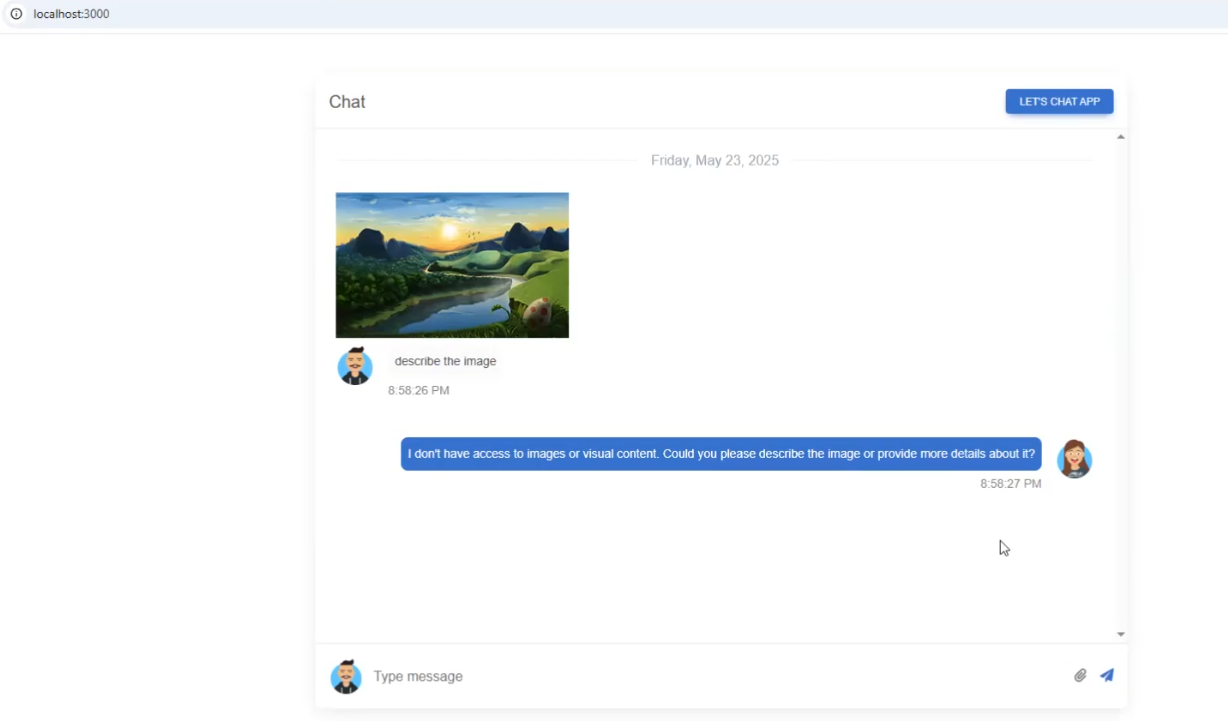
Figure 34
That's why when you upload a picture in the chat app and ask Qwen3 to describe it, the model responds that it does not have access to images or visual content.